
공유 서버 속 AI 워크로드 에너지, 어떻게 공정하게 나눌까?
관련 논문: An Energy Cost Model for AI Workloads under Shared Resource Environments — IEEE Internet of Things Journal (IoTJ) 2025
English version: Read in English
GitHub: vm-power-attribution (private)
들어가며: “같은 서버, 같은 요금?”
클라우드 서버 한 대를 두 팀이 나눠 쓴다고 상상해보세요. 한 팀은 ResNet으로 이미지를 1초에 수십 장 분류하고, 다른 팀은 Node.js 웹 서버를 돌립니다. 자원 할당은 동일 — CPU 2코어, 메모리 4GB, GPU 1장.
그런데 전기요금도 똑같아야 할까요?
저희 실험 결과, 두 워크로드의 실제 에너지 소비는 최대 11배 차이가 납니다. GPU 집약적인 AI 워크로드와 경량 웹 서버를 동일하게 청구하는 건 명백한 불공정입니다. 하지만 현실의 대부분 클라우드 과금 모델은 여전히 할당된 자원 기준으로 요금을 매깁니다.
이 포스트는 이 문제를 해결하기 위한 캡스톤 프로젝트의 구현 과정을 담은 튜토리얼입니다. 하드웨어 셋업부터 데이터 수집, 에너지 귀속 모델, 그리고 실험 결과까지 — 직접 재현할 수 있도록 단계별로 설명합니다.
전체 시스템 개요
먼저 전체 그림을 잡고 시작합니다. 시스템은 크게 세 부분으로 구성됩니다.
┌─────────────────────────────────────────────────────┐
│ 전체 시스템 구성 │
│ │
│ ┌──────────────┐ ┌──────────────────────────┐ │
│ │ 측정 레이어 │ │ 분석 레이어 │ │
│ │ │ │ │ │
│ │ RPICT4V3 │───▶│ ① system_power.tsv │ │
│ │ (AC 전력) │ │ wall/CPU/GPU/Mem │ │
│ │ │ │ │ │
│ │ RAPL │───▶│ ② workload_usage.tsv │ │
│ │ (CPU 전력) │ │ cpu%/gpu%/IO/Mem │ │
│ │ │ │ │ │
│ │ NVML │───▶│ ③ 에너지 귀속 모델 │ │
│ │ (GPU 전력) │ │ E_wi = f(자원별 규칙) │ │
│ │ │ │ │ │
│ │ cgroup v2 │───▶│ ④ 검증 │ │
│ │ (워크로드별) │ │ 오차 < 5% │ │
│ └──────────────┘ └──────────────────────────┘ │
└─────────────────────────────────────────────────────┘
아래 그림은 논문에서 제안하는 에너지 귀속 모델의 전체 구조입니다.
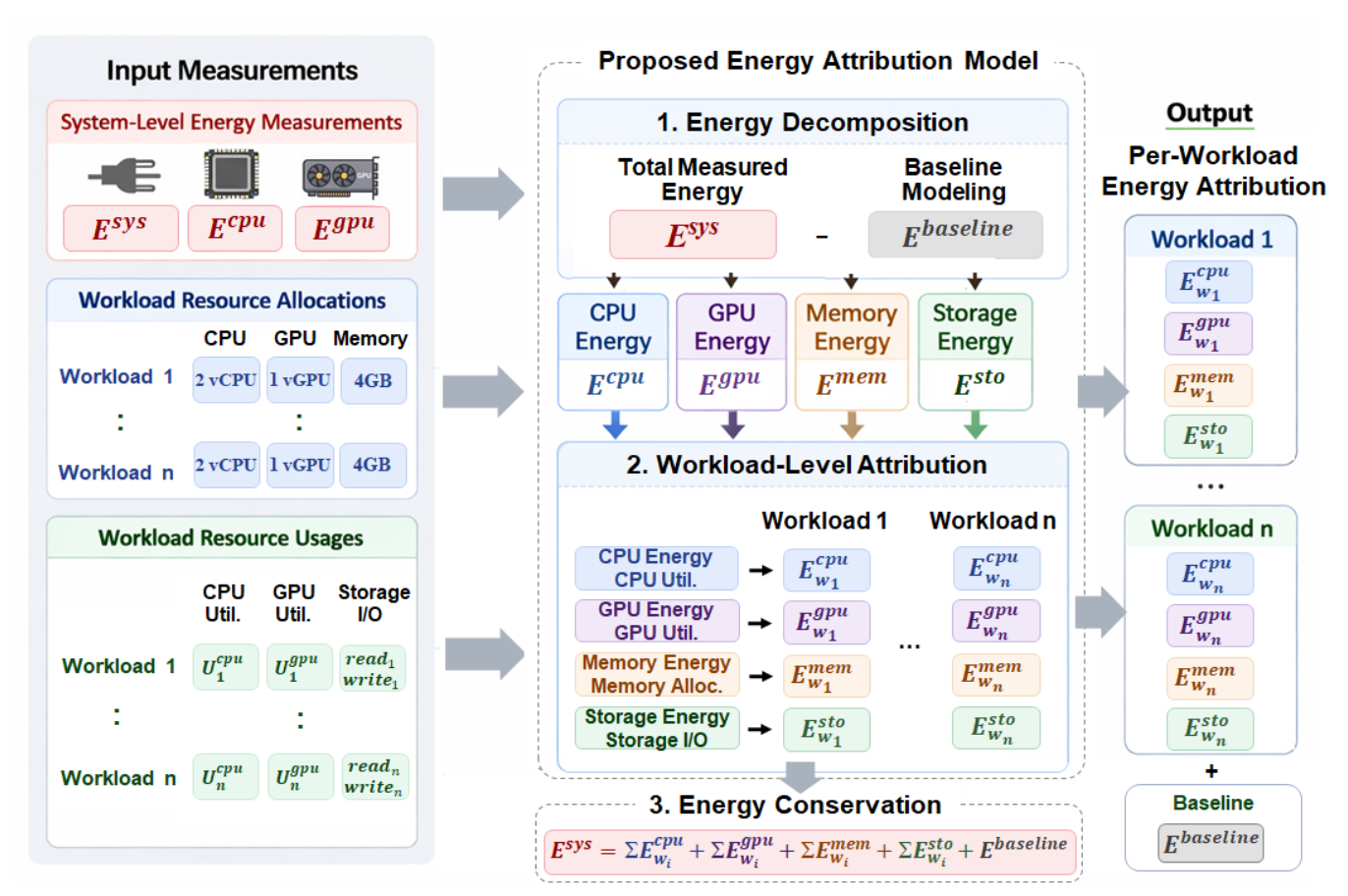 Fig. 2 — 입력 측정값에서 워크로드별 에너지 귀속 결과까지의 파이프라인
Fig. 2 — 입력 측정값에서 워크로드별 에너지 귀속 결과까지의 파이프라인
Step 1: 하드웨어 및 환경 구성
1-1. 하드웨어 구성
| 구성 요소 | 모델 | 역할 |
|---|---|---|
| 메인 서버 | Alienware Aurora R12 (i7-11700KF, RTX 3060 ×2, 32GB) | 워크로드 실행 |
| 전력 측정기 | RPICT4V3 + CT Sensor (SCT-006) | AC 벽면 전력 측정 |
| 수집 보드 | Raspberry Pi 4 | RPICT 시리얼 데이터 수집 |
RPICT4V3는 Raspberry Pi에 HAT 형태로 장착되며, CT 센서를 서버 전원 코드에 클램프로 물려 벽면 AC 전력을 1초 간격으로 측정합니다. 이 값이 가장 정확한 “지상 진실(ground truth)”이 됩니다.
1-2. 소프트웨어 스택
# 메인 서버 (Ubuntu 22.04)
sudo apt install -y python3-pip python3-venv
pip install torch torchvision transformers ultralytics
# RAPL 접근 권한 (CPU 전력 읽기)
sudo modprobe intel_rapl_common
# nvidia-smi 확인 (GPU 전력 읽기)
nvidia-smi --query-gpu=power.draw --format=csv
1-3. cgroup v2 설정 — 워크로드 격리
가장 중요한 셋업 단계입니다. cgroup v2를 사용해 각 워크로드를 별도의 슬라이스에 격리해야 CPU 사용량, 메모리, I/O를 워크로드 단위로 추적할 수 있습니다.
# yolo.slice: AI 워크로드용 (CPU 0-1, 최대 4GB)
sudo mkdir -p /sys/fs/cgroup/yolo.slice
echo "0-1" | sudo tee /sys/fs/cgroup/yolo.slice/cpuset.cpus
echo "0" | sudo tee /sys/fs/cgroup/yolo.slice/cpuset.mems
echo "4294967296" | sudo tee /sys/fs/cgroup/yolo.slice/memory.max # 4GB
# nodejs.slice: 웹 서버 워크로드용 (CPU 2-3, 최대 4GB)
sudo mkdir -p /sys/fs/cgroup/nodejs.slice
echo "2-3" | sudo tee /sys/fs/cgroup/nodejs.slice/cpuset.cpus
echo "0" | sudo tee /sys/fs/cgroup/nodejs.slice/cpuset.mems
echo "4294967296" | sudo tee /sys/fs/cgroup/nodejs.slice/memory.max
왜 cgroup이 필요한가? 공유 서버에서 여러 워크로드가 동시에 실행될 때, “워크로드 A가 CPU를 얼마나 썼는가”를 알아야 에너지를 귀속할 수 있습니다. cgroup은 OS 커널이 제공하는 가장 정확한 워크로드별 자원 추적 메커니즘입니다.
Step 2: 데이터 수집 파이프라인
환경이 갖춰졌으면 이제 전력을 측정할 차례입니다. 세 종류의 로거가 각자 다른 계층에서 데이터를 가져옵니다 — 하나라도 빠지면 에너지 귀속 계산이 불완전해집니다.
전력 측정은 세 가지 로거가 병렬로 실행되며, 각자 다른 계층의 데이터를 수집합니다.
실험 실행 중
│
├── host_logger.py ──▶ RAPL(CPU 전력) + NVML(GPU 전력) → CSV
├── cgroup_logger.py ──▶ 워크로드별 CPU%, 메모리, I/O → CSV
└── rpict_logger.py ──▶ AC 벽면 전력 → CSV (Raspberry Pi에서 실행)
2-1. host_logger.py — CPU·GPU 전력 수집
전체 시스템의 CPU 패키지 전력(RAPL)과 GPU 전력(nvidia-smi)을 1초 간격으로 수집합니다.
class RAPLReader:
"""Intel RAPL 에너지 카운터를 읽어 순간 전력(W)으로 변환"""
RAPL_BASE = "/sys/class/powercap/intel-rapl"
def read_power(self) -> dict:
current_time = time.time()
current_energy = {}
for name, path in self.domains.items():
try:
energy_uj = int(path.read_text().strip())
current_energy[name] = energy_uj
except (PermissionError, FileNotFoundError):
continue
power = {}
if self.prev_time is not None:
dt = current_time - self.prev_time
for name, energy in current_energy.items():
if name in self.prev_energy:
delta = energy - self.prev_energy[name]
if delta < 0:
delta += 2**32 # 오버플로우 처리
power[name] = (delta / 1_000_000) / dt # μJ → W
...
핵심은 RAPL 카운터의 연속 차분으로 순간 전력을 계산하는 것입니다. RAPL은 누적 에너지(μJ)를 제공하므로, 두 시점 사이의 차이를 시간으로 나눕니다.
실행 방법:
# 기본 실행 (Ctrl+C로 종료)
python3 scripts/measurement/host_logger.py -o data/raw/alienware/phase3_fixed/baseline_host.csv
# 60초 동안 0.5초 간격으로 수집
python3 scripts/measurement/host_logger.py -d 60 -i 0.5 -o baseline_host.csv
출력 CSV 컬럼: timestamp, rapl_package_w, gpu0_power_w, gpu1_power_w, gpu0_util_pct, gpu1_util_pct
2-2. cgroup_logger.py — 워크로드별 자원 사용량
각 워크로드가 실제로 얼마나 CPU를 쓰는지, 메모리와 I/O는 얼마나 발생시키는지를 cgroup v2 파일시스템에서 직접 읽습니다.
class CgroupReader:
"""cgroup v2 통계 읽기"""
def read_cpu_stat(self) -> Dict:
"""cpu.stat에서 실제 CPU 사용 시간(μs) 읽기"""
stat_file = self.path / "cpu.stat"
content = stat_file.read_text()
result = {}
for line in content.strip().split('\n'):
key, value = line.split()
result[key] = int(value)
return result
def get_cpu_percent(self) -> float:
"""두 측정 시점 사이의 CPU 사용률(%) 계산"""
now = self.read_cpu_stat()
elapsed_wall = time.time() - self.prev_time
elapsed_cpu_usec = now['usage_usec'] - self.prev_cpu_usage
# num_cpus 기준 정규화
return (elapsed_cpu_usec / 1e6) / elapsed_wall * 100
실행 방법:
# yolo.slice와 nodejs.slice 동시 모니터링
python3 scripts/measurement/cgroup_logger.py \
-c yolo.slice nodejs.slice \
-o data/raw/alienware/phase3_fixed/concurrent_cgroup.csv \
-d 90
2-3. rpict_logger.py — AC 벽면 전력 (Raspberry Pi)
Raspberry Pi에서 RPICT4V3의 시리얼 출력을 파싱하여 AC 전력을 기록합니다. 이 데이터는 에너지 보존 검증의 “정답”이 됩니다.
# Raspberry Pi에서 실행
python3 scripts/measurement/rpict_logger.py \
-p /dev/ttyAMA0 \
-o /home/pi/rpict_log.csv
시간 동기화가 핵심: 세 로거의 타임스탬프를 정렬해야 합니다. 메인 서버와 Raspberry Pi 모두 NTP 또는 PTP로 시간을 동기화하세요.
sudo timedatectl set-ntp true # 양쪽 모두
Step 3: 에너지 귀속 모델
데이터가 수집됐으면, 이제 그 데이터로 “누가 전기를 얼마나 썼는가”를 계산할 차례입니다. 단순히 반반 나누면 안 되는 이유, 그리고 자원마다 다른 규칙을 써야 하는 이유를 먼저 이해하고 코드로 넘어갑니다.
이 프로젝트의 핵심입니다. 수집한 데이터로 워크로드별 에너지를 얼마나 귀속할 것인가를 결정합니다.
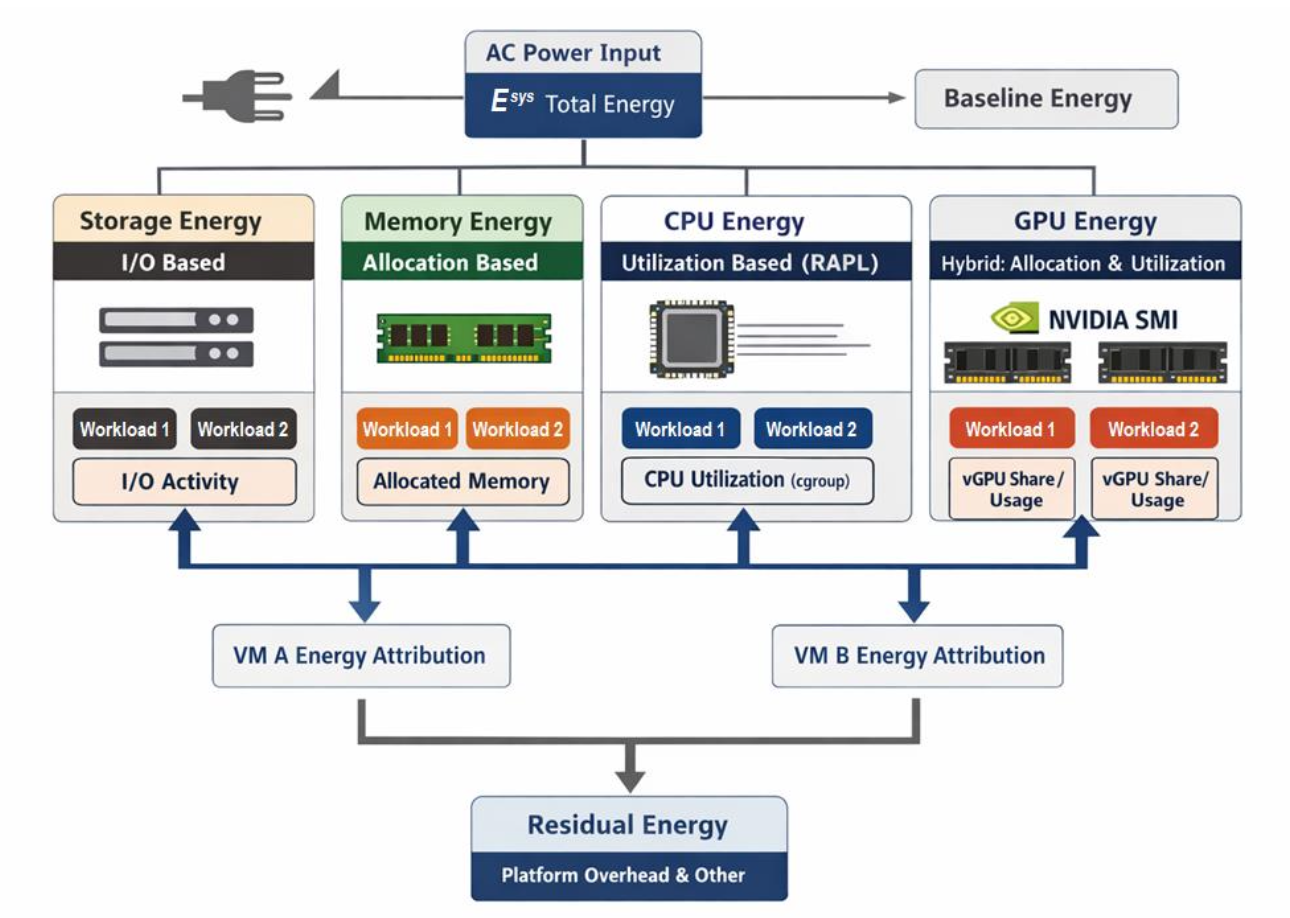 Fig. 1 — 자원 유형별로 다른 귀속 규칙을 적용하는 에너지 모델 구조
Fig. 1 — 자원 유형별로 다른 귀속 규칙을 적용하는 에너지 모델 구조
3-1. 왜 자원마다 다른 규칙이 필요한가?
자원 유형에 따라 에너지 소비 특성이 근본적으로 다릅니다.
| 자원 | 지배적 특성 | 귀속 방식 |
|---|---|---|
| CPU | 활동(utilization) 비례 | RAPL 측정값 × CPU 사용률 비율 |
| GPU | 할당 baseline + 활동 | 할당 비례(base) + 사용률 비례(activity) |
| Memory | 정적 refresh 전력 지배 | 할당량 비례 (사용률 X) |
| Storage | I/O 활동 비례 | 읽기/쓰기 바이트 × 단위 에너지 계수 β |
메모리가 왜 사용률이 아닌 할당량 기준인가?
DRAM은 데이터를 읽든 안 읽든 주기적으로 전하를 refresh해야 합니다. 이 정적 refresh 전력이 전체 메모리 전력의 대부분을 차지합니다. 워크로드가 메모리를 얼마나 자주 접근하는지와 무관하게, 얼마나 점유하고 있는지가 전력을 결정합니다.
LPDDR4 스펙 기준으로 0.2 W/GB를 사용합니다.
3-2. 수식 정의
시스템 전체 에너지를 자원별로 쪼갠 뒤, 각 워크로드에 배분하는 방식입니다. 수식이 낯설어도 구조는 단순합니다: “전체를 측정하고 → 기여도에 따라 나눈다”.
전체 시스템 에너지를 자원 별로 분해합니다:
\[E^{sys} = E^{cpu} + E^{gpu} + E^{mem} + E^{sto} + E^{other}\]각 워크로드 $w_i$가 책임지는 에너지는 다음과 같이 계산합니다:
CPU — “내가 CPU를 X% 썼으면, 전체 CPU 에너지의 X%를 부담한다”: \(E^{cpu}_{w_i} = E^{cpu}_W \cdot \frac{U^{cpu}_i}{\sum_j U^{cpu}_j}\)
GPU — “기본으로 점유한 몫(할당 비례) + 실제 연산한 만큼(사용률 비례)”: \(E^{gpu}_{w_i} = E^{gpu}_{idle} \cdot a_i + (E^{gpu} - E^{gpu}_{idle}) \cdot \frac{U^{gpu}_i}{\sum_j U^{gpu}_j}\)
Memory — “사용량과 무관하게, 점유한 용량만큼 부담한다”: \(E^{mem}_{w_i} = E^{mem}_{idle} \cdot \frac{m_i}{M}\)
에너지 보존 확인 — 워크로드 합계 + baseline = 시스템 측정값 (오차 없음): \(E^{sys} = E^{baseline} + \sum_{i=1}^{n} E_{w_i}\)
3-3. 코드 구현: extract_phase3_data.py
수식을 코드로 구현한 핵심 부분입니다. 전체 시스템에서 이 스크립트는 측정 데이터(CSV) → 귀속 결과(TSV)로 변환하는 역할을 합니다.
def process_data(data_dir, rpict_data, phases=None):
"""Phase 3 실험 데이터 처리: 측정값 → 귀속 결과"""
for phase_name, phase_type, wl_a, wl_b, concurrent_type in phases:
# 1. 안정 구간 추출 (시작 15초, 끝 5초 제거 — 과도 응답 제거)
host_stable = get_stable_range(host_raw)
# 2. 시스템 레벨 전력 측정값
cpu_power = avg(host_stable, "rapl_package_w") # Intel RAPL
gpu0_power = avg(host_stable, "gpu0_power_w") # nvidia-smi
gpu1_power = avg(host_stable, "gpu1_power_w")
wall_power = get_rpict_avg(rpict_data, t_start, t_end) # AC 입력
# 3. 메모리 전력: LPDDR4 스펙 기준 (0.2 W/GB × 32GB = 6.4W)
mem_power = 0.2 * 32
# 4. Others = Wall - CPU - GPU - Memory (PSU 손실, 팬, 마더보드 등)
others_power = wall_power - (cpu_power + gpu0_power + gpu1_power + mem_power)
# ── 워크로드별 귀속 ──────────────────────────────────────
for wl_name, cg_name, gpu_assign, gpu_cards in workloads_info:
cg_filtered = filter_cgroup(cg_stable, cg_name)
# CPU 사용률 (cgroup cpu.stat에서)
cpu_util = avg(cg_filtered, "cpu_percent")
# GPU: 물리적으로 분리 (yolo.slice → GPU0, nodejs.slice → GPU1)
if "yolo" in cg_name:
gpu_util = gpu0_util
gpu_pw = gpu0_power
else:
gpu_util = gpu1_util
gpu_pw = gpu1_power
# 메모리: 할당량 기준 (cgroup memory.max = 4GB)
mem_alloc_GB = 4.0
mem_attributed = 0.2 * mem_alloc_GB # = 0.8W per workload
전체 시스템 연관성: 이 스크립트는
host_logger.py가 생성한*_host.csv와cgroup_logger.py가 생성한*_cgroup.csv, 그리고 RPICT 측정값을 입력으로 받아system_power.tsv와workload_usage.tsv를 출력합니다. 이 TSV 파일들이 최종 그래프 생성(Fig. 4~8)의 입력이 됩니다.
Step 4: 실험 실행 (전체 파이프라인)
지금까지 설명한 환경 구성(Step 1), 로거(Step 2), 귀속 모델(Step 3)이 모두 연결되는 단계입니다. 이 순서대로 한 번만 실행하면 결과까지 자동으로 나옵니다.
4-1. 의존성 설치
# 레포 클론 후
cd vm-power-attribution
python3 -m venv venv && source venv/bin/activate
pip install -r requirements.txt
# AI 워크로드용 별도 가상환경 (CUDA 필요)
cd scripts/workloads
python3 -m venv yolo_venv && source yolo_venv/bin/activate
pip install torch torchvision transformers ultralytics
4-2. cgroup 설정
sudo ./scripts/workloads/setup_cgroups.sh
4-3. 실험 실행
# 전체 실험 자동화 (sudo 필요: cgroup 제어)
sudo -E ./scripts/workloads/run_experiment_phase3.sh
이 스크립트는 다음 순서로 16개 실험 Phase를 자동 실행합니다:
Baseline (60초)
↓ (cooldown 20초)
Solo 실행 5개: YOLO, ResNet18, GPT-2, PyTorch GEMM, Node.js (각 90초)
↓
AI+Node.js 동시 실행 4개: YOLO+Node, ResNet+Node, GPT2+Node, PyTorch+Node
↓
AI+AI 동시 실행 6개: YOLO+ResNet, YOLO+GPT2, ResNet+GPT2, ...
4-4. 데이터 추출 및 분석
# 측정값 → 귀속 결과 TSV 변환
python3 scripts/analysis/extract_phase3_data.py --run run1
# 결과 확인
cat reports/phase3/system_power.tsv
cat reports/phase3/workload_usage.tsv
# 그래프 생성 (Fig. 4~8 재현)
python3 scripts/analysis/comprehensive_analysis.py
결과: 할당 기반 과금의 불공정성을 수치로 증명
실험 전체 흐름 한눈에 보기
아래 그래프는 실험 전체를 시간 순서대로 찍은 전력 프로파일입니다. 왼쪽부터 idle → 솔로 실행 → 동시 실행 순으로 진행되며, AI 워크로드가 시작되는 순간 전력이 얼마나 급격히 오르는지 한눈에 확인할 수 있습니다.
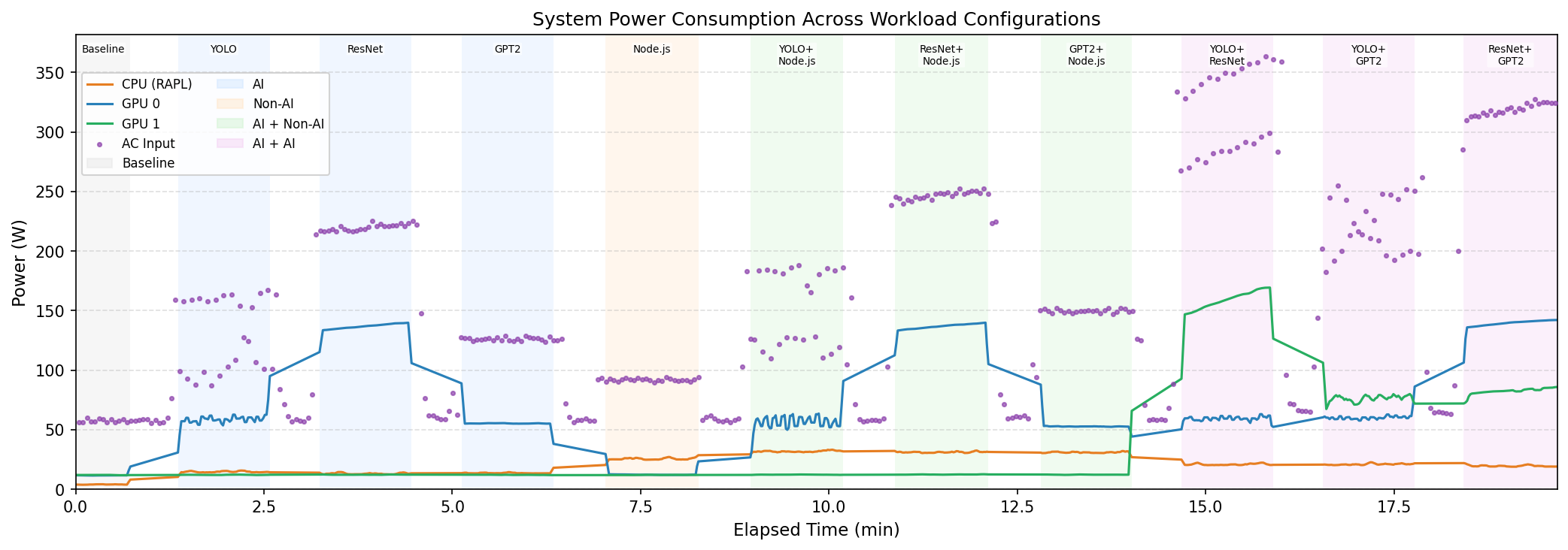 Fig. 3 — idle에서 ResNet 실행으로 전환되는 순간 GPU 전력이 ~15W → ~150W로 수직 상승. 오른쪽으로 갈수록 동시 실행 구간.
Fig. 3 — idle에서 ResNet 실행으로 전환되는 순간 GPU 전력이 ~15W → ~150W로 수직 상승. 오른쪽으로 갈수록 동시 실행 구간.
솔로 실행: 에너지 구조 분석
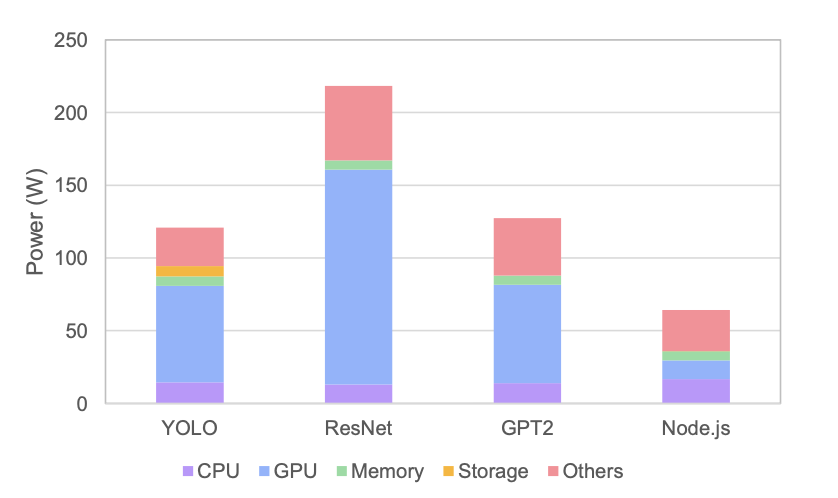 Fig. 4 — 워크로드별 시스템 전력 분해. AI 워크로드는 GPU가 전체의 53~68%를 차지.
Fig. 4 — 워크로드별 시스템 전력 분해. AI 워크로드는 GPU가 전체의 53~68%를 차지.
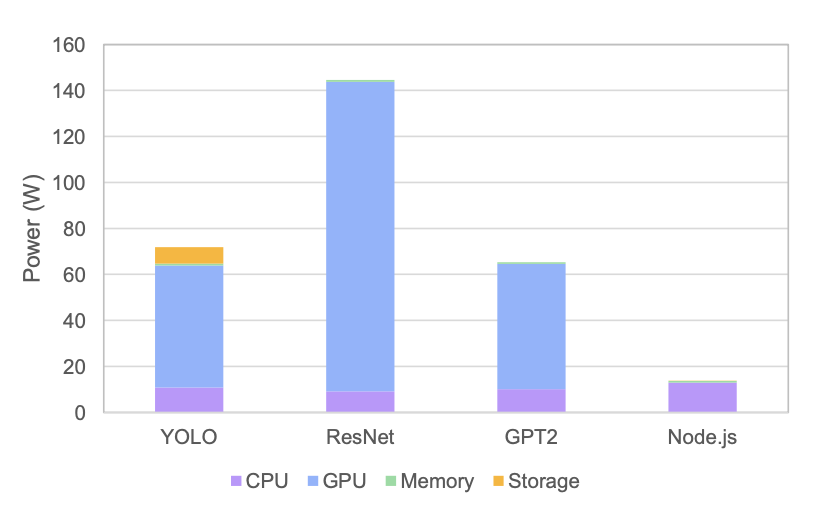 Fig. 5 — baseline 제거 후 워크로드가 유발한 순수 전력. ResNet과 Node.js의 차이가 더욱 선명.
Fig. 5 — baseline 제거 후 워크로드가 유발한 순수 전력. ResNet과 Node.js의 차이가 더욱 선명.
실험을 통해 측정한 주요 수치입니다:
| 워크로드 | CPU 전력 | GPU 전력 | Memory 전력 | 합계 |
|---|---|---|---|---|
| ResNet18 | ~9W | ~118W | 0.8W | ~128W |
| YOLO Medium | ~10W | ~44W | 0.8W | ~55W |
| GPT-2 | ~9W | ~39W | 0.8W | ~49W |
| Node.js | ~20W | ~0.2W | 0.8W | ~21W |
ResNet : Node.js = 약 6.2배 — 같은 자원을 할당받았지만 에너지 소비는 6배 이상 차이납니다.
동시 실행: 공유 환경에서의 간섭
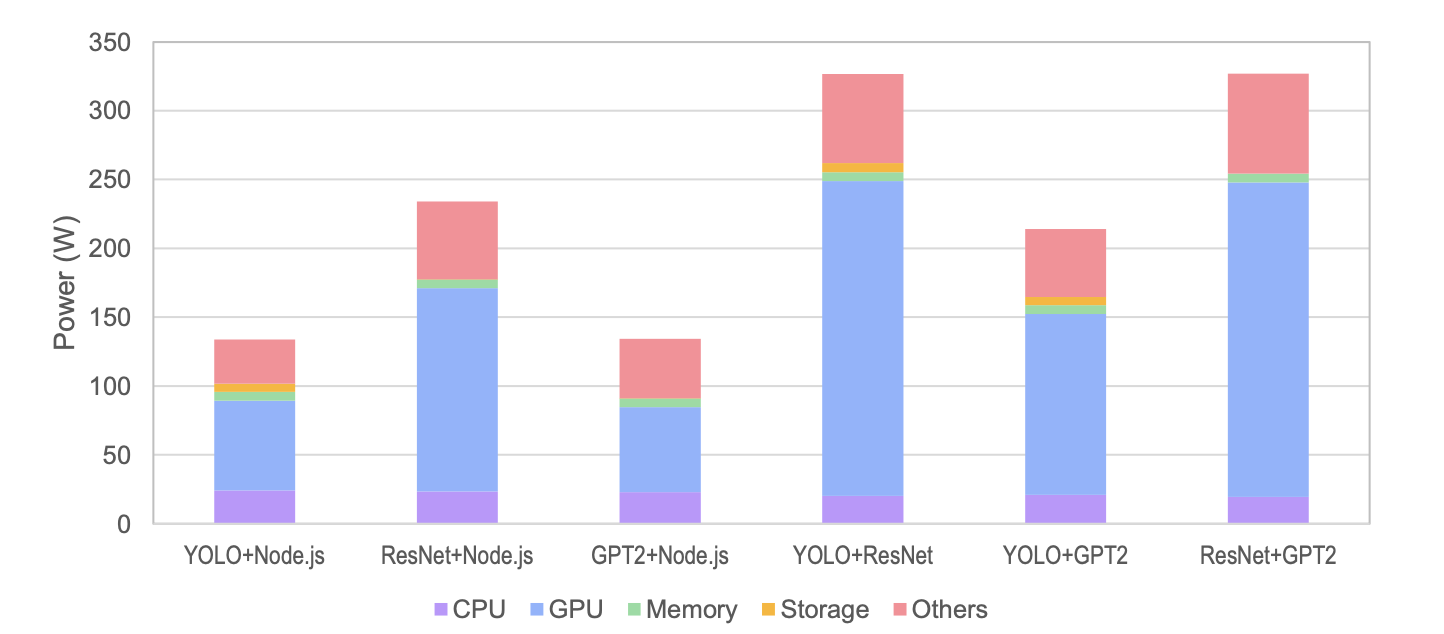 Fig. 6 — 두 워크로드 동시 실행 시 시스템 전력. AI+AI 조합에서 300W를 초과.
Fig. 6 — 두 워크로드 동시 실행 시 시스템 전력. AI+AI 조합에서 300W를 초과.
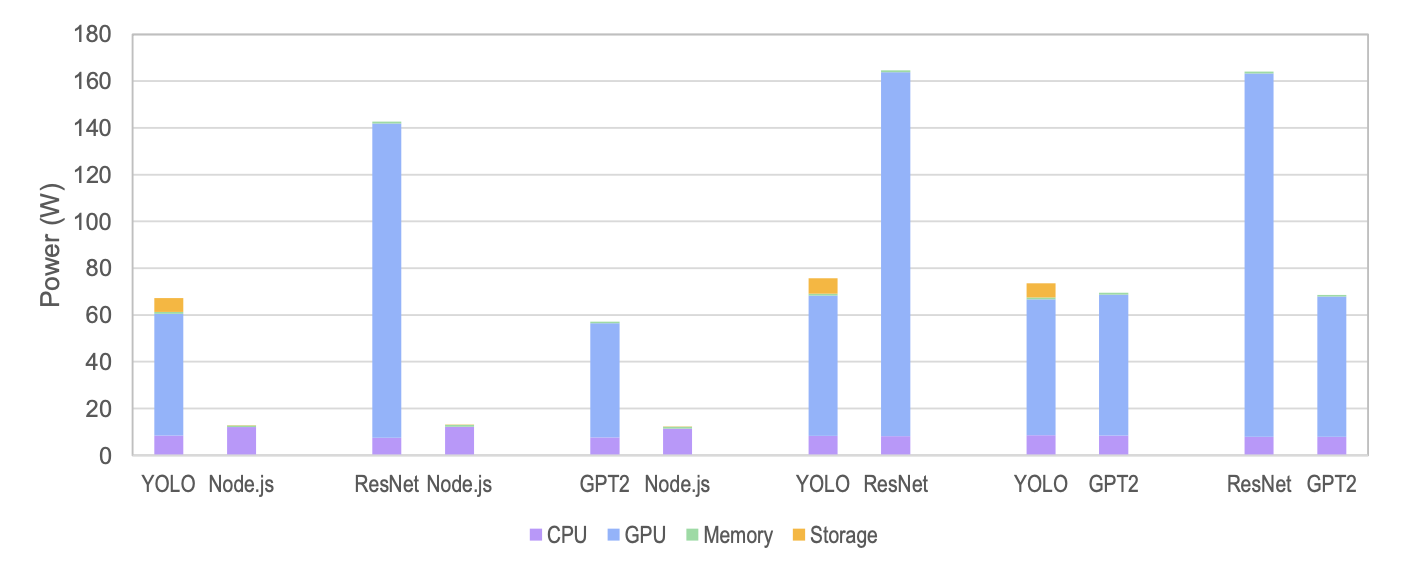 Fig. 7 — 제안 모델 적용 후 워크로드별 전력 귀속 결과. 솔로 실행 프로파일과 일관성 유지.
Fig. 7 — 제안 모델 적용 후 워크로드별 전력 귀속 결과. 솔로 실행 프로파일과 일관성 유지.
AI+Node.js 조합에서 에너지 차이는 4.7~11.0배까지 벌어집니다. 할당 기반 과금이라면 이 차이가 완전히 무시됩니다.
모델 검증: 오차 5% 미만
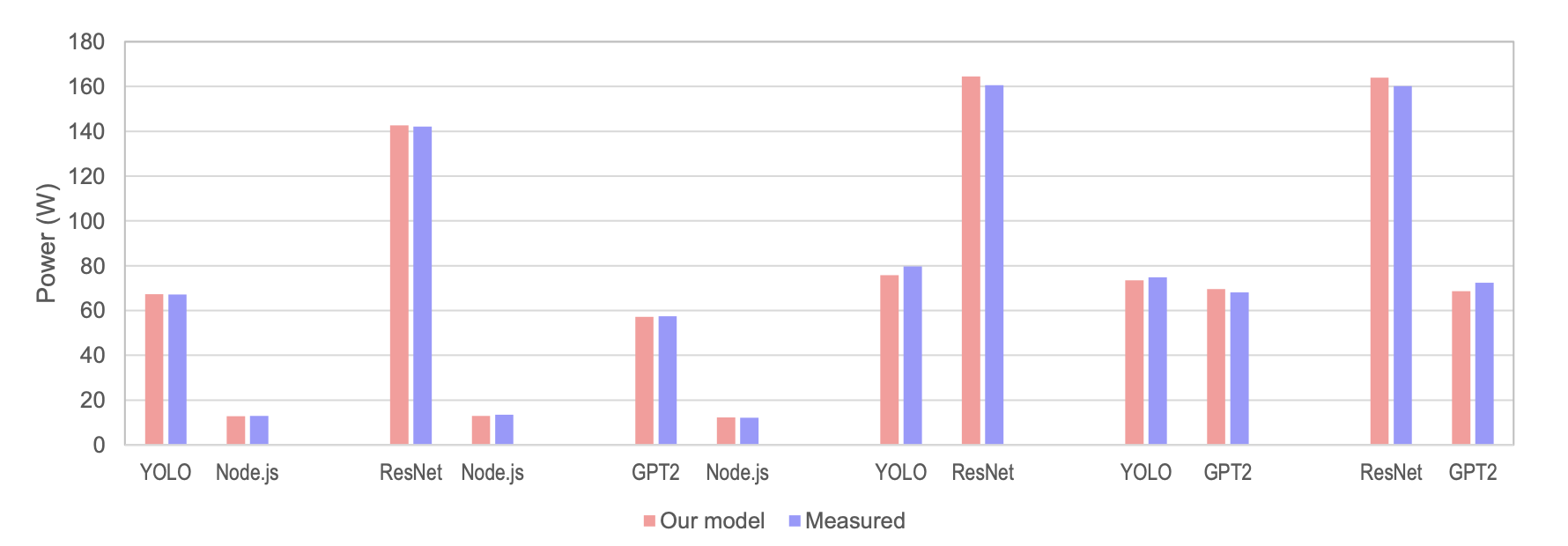 Fig. 8 — 모델 귀속값(빨간색)과 실제 측정값(파란색) 비교. 모든 조합에서 5% 이내.
Fig. 8 — 모델 귀속값(빨간색)과 실제 측정값(파란색) 비교. 모든 조합에서 5% 이내.
제안 모델의 귀속 오차는 다음과 같습니다:
- AI+Node.js 조합: AI 워크로드 0.1~0.4%, Node.js 0.4~4.1%
- AI+AI 조합 (비대칭): 평균 3.7%
- AI+AI 조합 (유사 전력): YOLO+GPT2 약 1.8~2.0%
추가 측정 장비 없이, 기존 OS 인터페이스(RAPL, nvidia-smi, cgroup)만으로 이 정확도를 달성했습니다.
겪은 시행착오들
직접 부딪히며 배운 내용들입니다. 비슷한 셋업을 시도한다면 미리 알아두면 좋습니다.
🔴 시행착오 1 — RPICT 타임스탬프 불일치
| 내용 | |
|---|---|
| 증상 | Run 2~6에서 RPICT wall power 값이 모두 baseline (~57W)과 동일하게 출력 |
| 원인 | 메인 서버(Alienware)와 Raspberry Pi의 시스템 시간이 수십 초 이상 어긋나 있어 타임스탬프 정렬 실패 |
| 해결 | 양쪽 모두 sudo timedatectl set-ntp true 로 NTP 동기화 → Run 1 데이터만 AC 전력 기준값으로 사용 |
🔴 시행착오 2 — AI+AI 동시 실행 구간 wall power 누락
| 내용 | |
|---|---|
| 증상 | YOLO+ResNet, YOLO+GPT2, ResNet+GPT2 조합에서 wall_W = 0 |
| 원인 | 두 AI 워크로드가 동시에 실행되는 시간대에 RPICT 로거가 응답하지 않아 측정 공백 발생 |
| 해결 | Fig. 6 그래프를 시각적으로 읽어 추정값 사용 (해당 구간 전후 평균 참조) |
🟡 시행착오 3 — 논문 수치와 raw data 불일치
| 내용 | |
|---|---|
| 증상 | 논문에 Node.js 시스템 전력 64W로 기재, raw data에서는 77.9W |
| 원인 | 논문은 CPU 주파수 고정(fixed) 조건 중 특정 run을 기준으로 기재, raw data는 6개 run 평균 |
| 해결 | 블로그와 포스터에는 raw data 기반 수치(6-run 평균) 사용 |
마치며
이 프로젝트는 한 가지 단순한 질문에서 시작했습니다: “같은 서버를 쓰는데, 전기요금도 같아야 하나?”
그 답을 구하기 위해 하드웨어 전력 측정기를 직접 연결하고, cgroup으로 워크로드를 격리하고, RAPL과 NVML로 컴포넌트별 전력을 읽고, 자원 유형별로 다른 귀속 규칙을 적용하는 모델을 만들었습니다.
결론은 명확합니다 — 할당 기반 과금은 AI 워크로드가 지배하는 현대 엣지 서버 환경에서 최대 11배의 불공정을 만들어냅니다. 그리고 이 불공정을 추가 장비 없이 5% 이내의 정확도로 바로잡을 수 있습니다.
이 연구 결과는 IEEE Internet of Things Journal (IoTJ)에 제출되었으며 현재 검토 중입니다.